边缘设备RK3588下RKNN的推理适配
这篇文章主要梳理一件事:如何把训练侧模型,稳定地落到 RK3588 上跑起来。
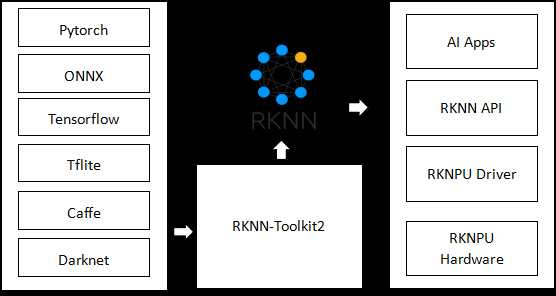
RKNN 是什么
RKNN 是瑞芯微(Rockchip)围绕自研 NPU 推出的完整软件栈,用来解决模型从训练框架到板端推理的落地问题。
常用到的核心组件有两个:
- RKNN-Toolkit2
运行在 PC 端(通常是 Ubuntu)的开发工具链,负责把第三方框架模型(如 PyTorch、TensorFlow、ONNX)转换、量化、优化为 .rknn 文件。
项目地址:
https://github.com/airockchip/rknn-toolkit2
- RKNN Runtime
运行在嵌入式板卡端(如 RK3588)的运行时库,负责加载 .rknn 模型并调用 NPU 执行推理。
如何判断我的设备是否支持RKNN
- 看型号,如rk3588,就是支持的
- 使用命令
sudo cat /sys/kernel/debug/rknpu/load

该结果表示有3个RK npu
RKNN 的典型工作流
从开发到部署,一般可以分成 4 个阶段:
- 模型转换
把 .onnx 或 .pt 模型导入 Toolkit,完成图转换与算子适配。
- 量化与优化
这是 RKNN 提速的关键步骤。NPU 更擅长整数计算(INT8),通常会把 FP32 模型量化为 INT8,在保证精度可接受的前提下换取更高吞吐和更低延迟。
- 模型导出
导出目标模型文件:.rknn。
- 板端推理
在 RK3588 上通过 C/C++ 或 Python 接口调用 Runtime,完成加载、预处理、推理和后处理。
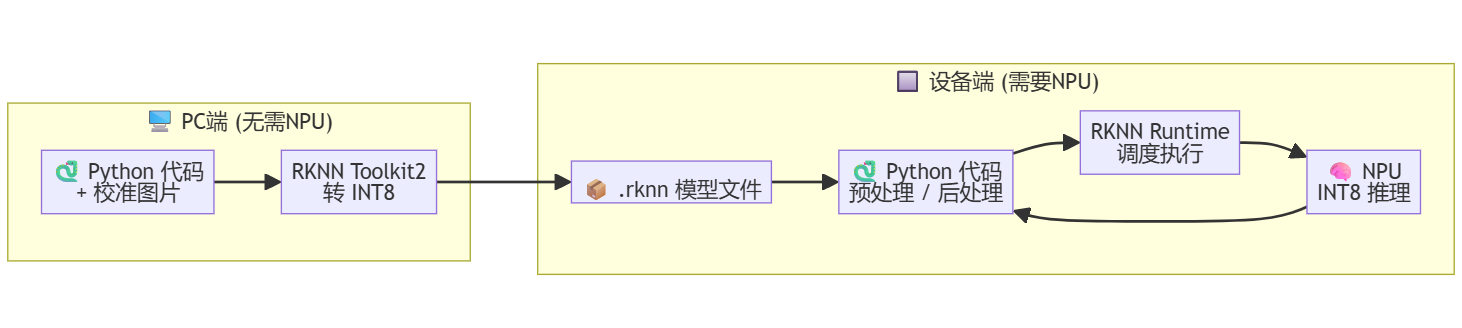
性能优化(1)— 模型的int8量化
众说周知,通用模型的精度是FP32的,而量化就是将FP32精度的权重降低至FP16,甚至是INT8,或者更极端一点的INT4。这样模型的计算量就会大幅减少,与之带来的后果也是准确度的下降。
BTW: 以前在jetson边缘设备下,是直接将yolo模型量化到FP16,使用官方一个命令即可。但是RK3588量化到FP16也不够,需要量化到INT8.
为什么需要量化到INT8?
为了性能!
不量化现在光YOLO最小尺寸的n级别模型,处理一张640*640的照片都需要160ms+。
这件事在 GPU 上可能没那么明显,但到了 RK3588 板子上就很现实:
一个RK3588的设备仅仅只有6TOPS的算力,官方标称还是在INT8 精度下算力为 6TOPS。
由于硬件设定,所以在INT8的精度才能更大程度的利用设备算力。INT8 模式下能充分利用三核 NPU,参考:https://www.iotdt.com/news/xingyezixun/1142.html
也就是说:只有量化到 INT8,才能跑出官方所宣传的“接近 6T”的理论算力;
但是,自古忠孝难两全,量化有代价,代价有两点
- 最常见的是精度会掉一点。
- 需要几百条数据重新标定对其误差。— 否则不可用
FP16和INT8量化有何区别?
FP16(16位浮点)是不需要校准数据的。 为什么?因为 FP32 转 FP16 只是把数字的“小数点精度”砍掉了一半,它依然能表示很大或很小的数(动态范围没变)。这就好比你把一张高清图直接等比例缩小,虽然模糊了点,但颜色比例没变,不需要你额外告诉它“这张图哪里亮哪里暗”。
而 INT8(8位整数)不一样。 INT8 只能表示 256 个离散的数(-128 到 127)。要把 FP32 浩瀚的数值范围硬塞进 256 个格子里,就必须知道这批数据的最大值和最小值在哪里(这就是求缩放因子和零点)。怎么求?必须拿真实数据跑一遍,这就是校准。
与此同时,也就是引入了新的工作量,数据校准
如何量化?
rknn.config(target_platform='rk3588')
rknn.load_onnx(model='yolo.onnx')
rknn.build(do_quantization=True, dataset='./dataset.txt')
rknn.export_rknn('yolo_int8.rknn')
量化的命令简单,但量化校准的数据难标。此事暂且记下,先行寻找是否有开源的校准数据集
推荐实践
推荐RKNN转换链路
实际项目里,更推荐这条链路:
PyTorch (.pt) -> ONNX (.onnx) -> RKNN-Toolkit2 -> .rknn
原因很简单:ONNX 在中间层更通用,便于调试和排查算子兼容问题;如果直接从训练框架到 RKNN,遇到兼容性问题时排错成本更高。
遗留问题
- 以上只是yolo推理的问题,可能后续insightface估计会遇到更多的问题
参考文档
- 瑞芯微RK3588的NPU算力多少-RK3588实际应用性能表现与优化空间https://www.iotdt.com/news/xingyezixun/1142.html
版权声明: 本文首发于 指尖魔法屋-边缘设备RK3588下RKNN的推理适配(https://blog.thinkmoon.cn/post/992-%E8%BE%B9%E7%BC%98%E8%AE%BE%E5%A4%87rk3588%E4%B8%8Brknn%E7%9A%84%E6%8E%A8%E7%90%86%E9%80%82%E9%85%8D/) 转载或引用必须申明原指尖魔法屋来源及源地址!