使用智谱api将长语音转文本
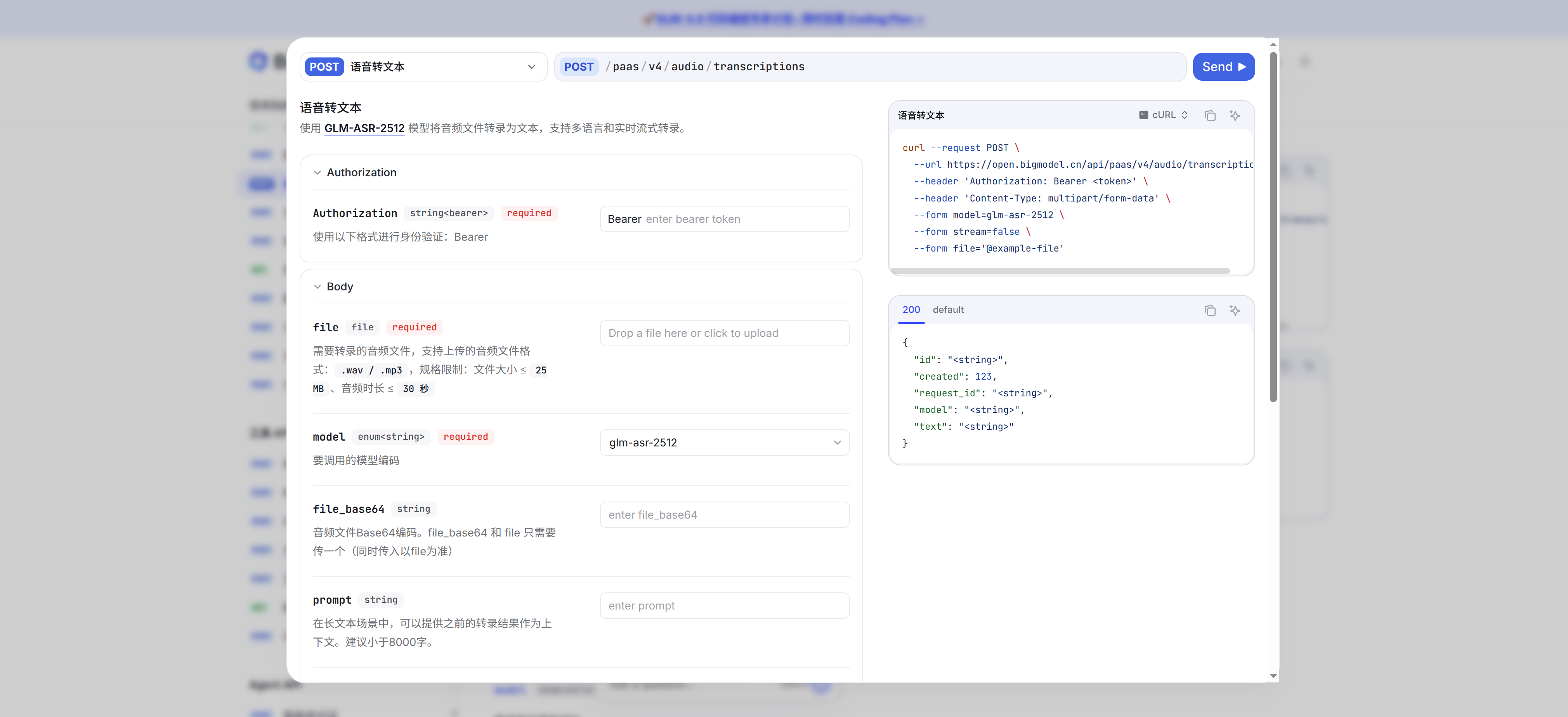
智谱AI语音识别API在准确性和响应速度方面表现出色,但受限于单次请求最大30秒的音频长度限制。本文基于pyannote.audio的语音活动检测(VAD)技术,实现了智能音频分块策略:在语音段落间隙处精确切割,避免截断语义单元;通过批量异步调用API接口,实现对长音频文件的完整转写;最终拼接处理结果输出。从Conda环境配置到生产代码实现,提供完整的可复现解决方案。
一、长语音转文本的核心挑战
主要的挑战是目前的条件没有合适的API。正好智谱API有token和API,先拿来用了。但是智谱API只能支持25M以下以及30s以内的语音。所以我们需要语音文件先断句,再分块,接着调用智谱API,最后拼接成最终结果。
三、关键技术:实现智能音频分块
这是自建系统的核心技术,也是本实践的重点。目标是在静音处切分音频,避免截断单词。
3.1 核心思想
- 加载音频:读取长音频文件。
- 检测静音:遍历音频,识别出静音段(声音能量低于阈值)。
- 标记边界:以静音为边界,切分语音。
- 生成音频块:保存为独立的短音频文件。
- 添加保护垫:在切分点两边保留一小段音频作为缓冲,防止截断。
3.2 三种实现方案
| 方案 | 优点 | 缺点 | 推荐场景 |
|---|---|---|---|
pydub | 极其简单,代码少 | 精度一般,噪音敏感 | 快速原型验证、干净录音 |
webrtcvad | 精度高,轻量快速 | API底层,代码复杂 | 对准确率有要求、生产环境 |
pyannote.audio | 效果最好,功能强大(含说话人分离) | 依赖重,资源消耗大 | 需要说话人分离、追求最佳效果 |
3.3 使用 pyannote.audio 进行分块(本实践选择)
pyannote.audio 是一个基于 PyTorch 的开源神经语音工具包,效果最好,且能同时完成说话人分离。选型原则:条件允许范围内,选最好!
但是本实践没有进行说话人分离
四、完整实践:使用pyannote.audio切割并调用API转写
实现一个完整的流程:使用 pyannote.audio 切割音频,然后调用智谱AI的API进行转写。
4.1 环境准备
首先,为了避免系统环境冲突,强烈建议创建一个虚拟环境。
安装依赖
依赖文件
name: audio_env
channels:
- conda-forge
- defaults
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
dependencies:
- _libgcc_mutex=0.1
- _openmp_mutex=5.1
- aom=3.9.1
- bzip2=1.0.8
- ca-certificates=2025.12.2
- cairo=1.18.0
- dav1d=1.2.1
- expat=2.7.3
- ffmpeg=7.1.0
- font-ttf-dejavu-sans-mono=2.37
- font-ttf-inconsolata=3.000
- font-ttf-source-code-pro=2.038
- font-ttf-ubuntu=0.83
- fontconfig=2.15.0
- fonts-conda-ecosystem=1
- fonts-conda-forge=1
- freetype=2.14.1
- fribidi=1.0.16
- gdk-pixbuf=2.42.12
- gmp=6.3.0
- graphite2=1.3.14
- harfbuzz=9.0.0
- icu=73.2
- lame=3.100
- ld_impl_linux-64=2.44
- lerc=4.0.0
- libabseil=20240722.0
- libass=0.17.3
- libdeflate=1.22
- libdrm=2.4.125
- libegl=1.7.0
- libexpat=2.7.3
- libffi=3.4.4
- libfreetype=2.14.1
- libfreetype6=2.14.1
- libgcc=15.2.0
- libgcc-ng=15.2.0
- libgl=1.7.0
- libglib=2.84.0
- libglvnd=1.7.0
- libglx=1.7.0
- libgomp=15.2.0
- libhwloc=2.12.1
- libiconv=1.18
- libjpeg-turbo=3.1.2
- libnsl=2.0.0
- libopenvino=2024.4.0
- libopenvino-auto-batch-plugin=2024.4.0
- libopenvino-auto-plugin=2024.4.0
- libopenvino-hetero-plugin=2024.4.0
- libopenvino-intel-cpu-plugin=2024.4.0
- libopenvino-intel-gpu-plugin=2024.4.0
- libopenvino-intel-npu-plugin=2024.4.0
- libopenvino-ir-frontend=2024.4.0
- libopenvino-onnx-frontend=2024.4.0
- libopenvino-paddle-frontend=2024.4.0
- libopenvino-pytorch-frontend=2024.4.0
- libopenvino-tensorflow-frontend=2024.4.0
- libopenvino-tensorflow-lite-frontend=2024.4.0
- libopus=1.6
- libpciaccess=0.18
- libpng=1.6.53
- libprotobuf=5.28.2
- librsvg=2.58.4
- libstdcxx=15.2.0
- libstdcxx-ng=15.2.0
- libtiff=4.7.0
- libuuid=1.41.5
- libva=2.23.0
- libvpx=1.14.1
- libwebp-base=1.6.0
- libxcb=1.17.0
- libxml2=2.13.9
- libzlib=1.3.1
- ncurses=6.5
- ocl-icd=2.3.3
- opencl-headers=2025.06.13
- openh264=2.5.0
- openssl=3.6.0
- pango=1.54.0
- pcre2=10.44
- pip=25.3
- pixman=0.46.4
- pthread-stubs=0.3
- pugixml=1.14
- python=3.10.19
- readline=8.3
- setuptools=80.9.0
- snappy=1.2.2
- sqlite=3.51.0
- svt-av1=2.3.0
- tbb=2022.3.0
- tk=8.6.15
- wayland=1.24.0
- wayland-protocols=1.47
- wheel=0.45.1
- x264=1!164.3095
- x265=3.5
- xorg-libice=1.1.2
- xorg-libsm=1.2.6
- xorg-libx11=1.8.12
- xorg-libxau=1.0.12
- xorg-libxdmcp=1.1.5
- xorg-libxext=1.3.6
- xorg-libxfixes=6.0.2
- xorg-libxrender=0.9.12
- xorg-xorgproto=2024.1
- xz=5.6.4
- zlib=1.3.1
- zstd=1.5.7
- pip:
- aiohappyeyeballs==2.6.1
- aiohttp==3.13.2
- aiosignal==1.4.0
- alembic==1.17.2
- antlr4-python3-runtime=4.9.3
- anyio=4.12.0
- asteroid-filterbanks==0.4.0
- async-timeout==5.0.1
- attrs==25.4.0
- certifi==2025.11.12
- cffi==2.0.0
- charset-normalizer==3.4.4
- click==8.3.1
- colorlog==6.10.1
- contourpy==1.3.2
- cycler==0.12.1
- docopt==0.6.2
- einops==0.8.1
- exceptiongroup==1.3.1
- filelock==3.20.1
- fonttools==4.61.1
- frozenlist==1.8.0
- fsspec==2025.12.0
- googleapis-common-protos==1.72.0
- greenlet==3.3.0
- grpcio==1.76.0
- h11==0.16.0
- hf-xet==1.2.0
- httpcore==1.0.9
- httpx==0.28.1
- huggingface-hub==0.23.5
- hyperpyyaml==1.2.2
- idna==3.11
- importlib-metadata==8.7.0
- jinja2==3.1.6
- joblib==1.5.3
- julius==0.2.7
- kiwisolver==1.4.9
- lightning==2.6.0
- lightning-utilities==0.15.2
- mako==1.3.10
- markdown-it-py==4.0.0
- markupsafe==3.0.3
- matplotlib==3.10.8
- mdurl==0.1.2
- mpmath==1.3.0
- multidict==6.7.0
- networkx==3.4.2
- numpy==1.26.4
- nvidia-cublas-cu12==12.1.3.1
- nvidia-cuda-cupti-cu12==12.1.105
- nvidia-cuda-nvrtc-cu12==12.1.105
- nvidia-cuda-runtime-cu12==12.1.105
- nvidia-cudnn-cu12==9.1.0.70
- nvidia-cufft-cu12==11.0.2.54
- nvidia-cufile-cu12==1.13.1.3
- nvidia-curand-cu12==10.3.2.106
- nvidia-cusolver-cu12==11.4.5.107
- nvidia-cusparse-cu12==12.1.0.106
- nvidia-cusparselt-cu12==0.7.1
- nvidia-nccl-cu12==2.20.5
- nvidia-nvjitlink-cu12==12.8.93
- nvidia-nvshmem-cu12==3.3.20
- nvidia-nvtx-cu12==12.1.105
- omegaconf==2.3.0
- opentelemetry-api==1.39.1
- opentelemetry-exporter-otlp==1.39.1
- opentelemetry-exporter-otlp-proto-common==1.39.1
- opentelemetry-exporter-otlp-proto-grpc==1.39.1
- opentelemetry-exporter-otlp-proto-http==1.39.1
- opentelemetry-proto==1.39.1
- opentelemetry-sdk==1.39.1
- opentelemetry-semantic-conventions==0.60b1
- optuna==4.6.0
- packaging==25.0
- pandas==2.3.3
- pillow==12.0.0
- primepy==1.3
- propcache==0.4.1
- protobuf==6.33.2
- pyannote-audio==3.1.1
- pyannote-core==5.0.0
- pyannote-database==5.1.3
- pyannote-metrics==3.2.1
- pyannote-pipeline==3.0.1
- pyannoteai-sdk==0.3.0
- pycparser==2.23
- pydub==0.25.1
- pygments==2.19.2
- pyparsing==3.2.5
- pysocks==1.7.1
- python-dateutil==2.9.0.post0
- pytorch-lightning==1.9.5
- pytorch-metric-learning==2.9.0
- pytz==2025.2
- pyyaml==6.0.3
- requests==2.32.5
- rich==14.2.0
- ruamel-yaml==0.18.16
- ruamel-yaml-clib==0.2.15
- safetensors==0.7.0
- scikit-learn==1.7.2
- scipy==1.15.3
- semver==3.0.4
- sentencepiece==0.2.1
- shellingham==1.5.4
- six==1.17.0
- socksio==1.0.0
- sortedcontainers==2.4.0
- soundfile==0.13.1
- speechbrain==1.0.3
- sqlalchemy==2.0.45
- sympy==1.14.0
- tabulate==0.9.0
- tensorboardx==2.6.4
- threadpoolctl==3.6.0
- tomli==2.3.0
- torch==2.4.0+cu121
- torch-audiomentations==0.12.0
- torch-pitch-shift==1.2.5
- torchaudio==2.4.0+cu121
- torchcodec==0.7.0
- torchmetrics==0.11.4
- torchvision==0.19.0+cu121
- tqdm==4.67.1
- triton==3.0.0
- typer==0.20.0
- typer-slim==0.20.0
- typing-extensions==4.15.0
- tzdata==2025.3
- urllib3==2.6.2
- yarl==1.22.0
- zipp==3.23.0
安装依赖
将上述内容保存为 environment.yml 文件,然后执行以下命令安装所有依赖:
# 从环境文件创建并激活环境(推荐方式)
conda env create -f environment.yml
conda activate audio_env
# 或者直接指定Python版本创建环境(备用方式)
# conda create -n audio_env python=3.10
# conda activate audio_env
注意:如果创建环境时遇到网络问题,可以考虑添加清华源等国内镜像源来加速下载。
4.2 完整 Python 代码
将以下代码保存为 voice2text.py,请修改为你的智谱api key和huggingface token
import os
import time
import torch
import requests
import shutil
from pyannote.audio import Pipeline
from pydub import AudioSegment
from pathlib import Path
# --- 自动配置环境路径 ---
ffmpeg_path = shutil.which("ffmpeg")
if ffmpeg_path:
AudioSegment.converter = ffmpeg_path
class AudioTranscriber:
def __init__(self, api_key):
self.api_key = api_key
self.api_url = "https://open.bigmodel.cn/api/paas/v4/audio/transcriptions"
def split_audio_with_pyannote(self, audio_file_path, output_dir="audio_chunks"):
print("开始加载 VAD 模型...")
# 1. 自动检测并使用 GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"正在使用设备: {device}")
# 2. 加载 Pipeline 并移动到 GPU
pipeline = Pipeline.from_pretrained(
"pyannote/voice-activity-detection",
use_auth_token="xxx"
).to(device)
print("正在进行语音活动检测 (VAD)...")
Path(output_dir).mkdir(exist_ok=True)
# 运行检测
vad = pipeline(audio_file_path)
audio = AudioSegment.from_file(audio_file_path)
chunk_files = []
for i, segment in enumerate(vad.itersegments()):
start_time, end_time = segment.start * 1000, segment.end * 1000
chunk = audio[start_time:end_time]
chunk_filename = f"chunk_{i:04d}.wav"
chunk_path = os.path.join(output_dir, chunk_filename)
chunk.export(chunk_path, format="wav")
chunk_files.append({"path": chunk_path, "start": segment.start, "end": segment.end, "duration": segment.end - segment.start})
print(f"已生成: {chunk_filename}")
return chunk_files
def transcribe_audio_chunk(self, audio_file_path):
"""调用智谱AI进行转写"""
try:
with open(audio_file_path, 'rb') as f:
headers = {'Authorization': f'Bearer {self.api_key}'}
files = {'file': f}
data = {'model': 'glm-asr-2512', 'stream': 'false'}
# 注意:requests 会自动读取环境变量中的代理设置
response = requests.post(self.api_url, headers=headers, files=files, data=data, timeout=60)
if response.status_code == 200:
return response.json().get('text', '')
except Exception as e:
print(f"转写出错: {e}")
return ""
def transcribe_all(self, chunk_files, output_file="result.txt"):
results = []
for i, chunk in enumerate(chunk_files, 1):
print(f"正在转写 {i}/{len(chunk_files)}...")
text = self.transcribe_audio_chunk(chunk['path'])
if text:
results.append(f"[{chunk['start']:.2f}s] {text}")
time.sleep(0.5) # 频率控制
with open(output_file, 'w', encoding='utf-8') as f:
f.write("\n".join(results))
print(f"保存成功:{output_file}")
def main():
# --- 代理配置 ---
# 如果有配置代理,访问 HuggingFace 必须有这几行。没有代理就算了
proxy = "socks5://127.0.0.1:10808"
os.environ['HTTP_PROXY'] = proxy
os.environ['HTTPS_PROXY'] = proxy
# 智谱 API 走国内直连,不走代理(非常重要,否则可能报 403 或超时)
os.environ['NO_PROXY'] = 'open.bigmodel.cn'
api_key = "xxx"
audio_file = "./2024_08_15_11_23_14.wav"
transcriber = AudioTranscriber(api_key)
try:
chunks = transcriber.split_audio_with_pyannote(audio_file)
if chunks:
transcriber.transcribe_all(chunks)
except Exception as e:
print(f"运行失败: {e}")
if __name__ == "__main__":
main()
4.3 运行与结果
直接python voice2text.txt
刚开始会生成很多个chunk
已生成: chunk_0000.wav
已生成: chunk_0001.wav
已生成: chunk_0002.wav
已生成: chunk_0003.wav
已生成: chunk_0004.wav
已生成: chunk_0005.wav
已生成: chunk_0006.wav
然后会开始调用智谱api的接口转写txt
正在转写 100/132...
正在转写 101/132...
正在转写 102/132...
正在转写 103/132...
正在转写 104/132...
正在转写 105/132...
正在转写 106/132...
正在转写 107/132...
最后会将结果输出到result.txt
正在转写 129/132...
正在转写 130/132...
正在转写 131/132...
正在转写 132/132...
保存成功:result.txt
参考文献
- PyAnnote.audio 官方文档 - 核心语音处理库
- PyAnnote.audio 语音活动检测 - VAD模型
- Pydub 官方文档 - 音频文件处理库
- 智谱AI API 文档 - 语音识别API
版权声明: 本文首发于 指尖魔法屋-使用智谱api将长语音转文本(https://blog.thinkmoon.cn/post/990-%E4%BD%BF%E7%94%A8%E6%99%BA%E8%B0%B1api%E5%B0%86%E9%95%BF%E8%AF%AD%E9%9F%B3%E8%BD%AC%E6%96%87%E6%9C%AC/) 转载或引用必须申明原指尖魔法屋来源及源地址!